What happens during training
After the examples are submitted, the crawler starts examining the files and providing them to the learning algorithms. If the number of files in a folder is very large, a sampling algorithm samples the folder several times and checks for convergence.
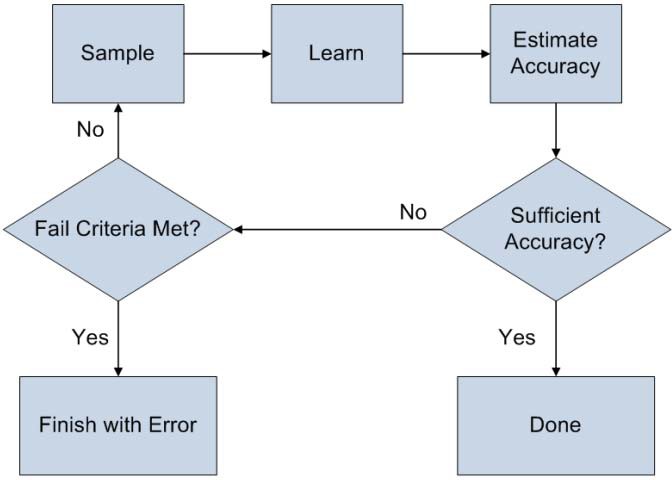
If learning is successful (meaning that the data is “learnable”), the following window appears:
.jpg)
- The sensitivity level is set to “Default,” an optimal trade-off between false positives (unintended matches) and false negatives (undetected matches). To change the sensitivity
level, click Default, which opens the Update machine learning Content Classifier window:
.jpg)
It is important to consider the percentage of unintended and undetected matches before changing the sensitivity level. For example, selecting “Narrow” increases the expected number of undetected matches without reducing the expected number of unintended matches. It is, therefore, highly undesirable.
- The training is performed ignoring outliers, or examples that could be labeled “positive,” but that do not seem to belong to the positive
set.
To avoid ignoring outliers, administrators can click Yes next to “Ignore outlier documents” and change it to No.