Quantifying risk
Each person has an intuitive notion regarding risk; however, assigning a meaningful and consistent risk metric is difficult. Although some clear high-risk cases are easy to discern—such as a file with thousands of credit-card numbers that was sent in the middle of the night to a dubious destination by an employee with a poor record—it is much harder to decide about cases with an ambiguous data classification, or incidents within the “gray area”. These can stem from an employee’s mistakes or broken business processes or from sophisticated insiders who attempt to make their activity look “normal”.
Systematic approaches to risk quantification and management were first developed in the field of insurance and were based on the expectation value of the loss. Broadly speaking, this can be expressed as:
Risk = (Probability of “bad” events)•(Amount of loss associated with the events)
To this day, insurance underwriting is still based on this basic formula, which is also widely used for quantifying other risks, and it is, by large, the canonical measure for risk quantification.
The intimate acquaintance of content-aware DLP with sensitive content, whether that be intellectual property or regulated data sets, allows the system to assess the potential damages or losses associated with cases in which a certain type of content is stolen or otherwise exposed.
In general, the impact would be based on the classification and the size of the exposed data: an incident with a single credit card data number is much less severe than an incident with a hundred numbers, which is yet less severe than stealing credentials for a database with millions of sensitive records. In order to assess the risk, we need also to assess the probabilities of the various possible “scenario classes.” Was it a deliberate data theft? In this case, the impact can be very large, and there is an urgent need to address the problem. Was it a broken business process, where information is exchanged in a non-secure manner? In this case, the risk is enduring and requires systematic, yet not urgent, action. Or was it was a one-time mistake?
On the other hand, false positives and events of low importance, such as personal communication, also convey cost, associated with the time that was spent and the attention that was devoted for their analysis, as well as the “opportunity cost”, associated with missing high-impact events that got “lost in the shuffle”. It is therefore also important to be able to identify those superfluous incidents, whenever possible.
In order to assess the probabilities, our researchers have developed an advanced tool based on a technology called Bayesian Belief Networks, that utilizes the various observables and indicators to assess the plausibility of the various scenarios by combining expert’s knowledge, deep learning techniques, and statistical inference.
A key observation in this respect is that we need to see behind the single alert or incident. Before assessing the risks, the system first correlates related incidents into cases that aggregate various incidents based on key attributes such as the source, destination, and data types, as well as more subtle patterns that take into account various similarity measures between incidents.
After constructing the various cases, the probabilities of the various scenario classes or possible explanations are assessed using special Bayesian Belief Networks that were developed and trained for these specific classes. The various explanations compete with each other, and, eventually, the product obtains the likelihood of each scenario, as illustrated in Figure 1:
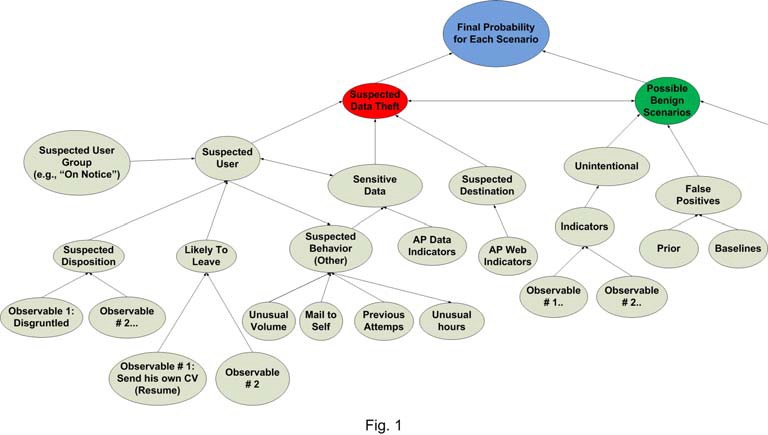
Bayesian networks simplify the assessment of likelihood based on multiple observables and indicators using the notion of conditional independence in various hierarchical levels. The system can group a relatively small number of observables and indicators—such as the employee sent his own resume to another company’s HR and sent an email that suggests a negative disposition to their boss—to assess the plausibility of various hypotheses —such as that the employee is likely to leave soon. This could indicate that an incident where he sent source-code to his own Gmail account is more likely to be data theft incident than a case in which he merely wanted to work on the code on his spare time.
On the other hand, in some cases the content itself may provide strong indication that the incident is a data theft incident—for example, there is no conceivable reason to send the Security Account Manager (SAM) database to an external Gmail address.
The results are automatically explained on cards in the Forcepoint DLP incident risk ranking report:
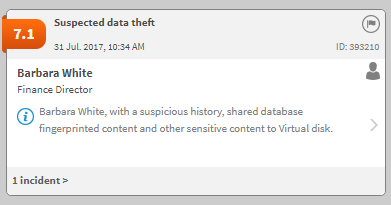
.png)
In some cases, the system identifies patterns of data breached that are more likely to be a broken business practice:
.png)
In other cases, it would be hard (or impossible) to identify the scenario. The system renders these as “uncategorized”:
.png)