Scanning Data Sources
Scanning process and statuses
To review scans and their statuses go to .
The scanning process discovers and analyzes files across all configured data sources. It operates in three steps:
Discovery
This step ensures that every file and folder is identified and that access permissions are understood.
- The system searches through all files and folders.
- If a specific path has not been set, the entire Data Source will be scanned.
- Metadata (path, size, format, etc.) and permissions are extracted and recorded for each file.
 Not Started: Data Source has been added but the scan has not started.
Not Started: Data Source has been added but the scan has not started.  Queued: Scan has been put into the queue for the execution.
Queued: Scan has been put into the queue for the execution. Failed To Start: Scan unable to start, usually due to issues with permissions or network.
Failed To Start: Scan unable to start, usually due to issues with permissions or network. In Progress: Scan is running and processing data.
In Progress: Scan is running and processing data. Cancelled: Scan was manually stopped or automatically aborted.
Cancelled: Scan was manually stopped or automatically aborted.  Completed: Scan has finished processing.
Completed: Scan has finished processing.
These statuses can be seen in the Last Scan Status column.
Metadata classification
This is the continuation of the Discovery process. A detailed analysis of each file's metadata is performed. Metadata information is processed for each file that has been collected as part of the Discovery step.
- File name, file type, and file path
- Content length
- Timestamps (Last Modified, Last Accessed, Created)
- Metadata and Cloud labels (e.g., SMB labels are metadata-written)
- File permissions (if enabled to fetch)
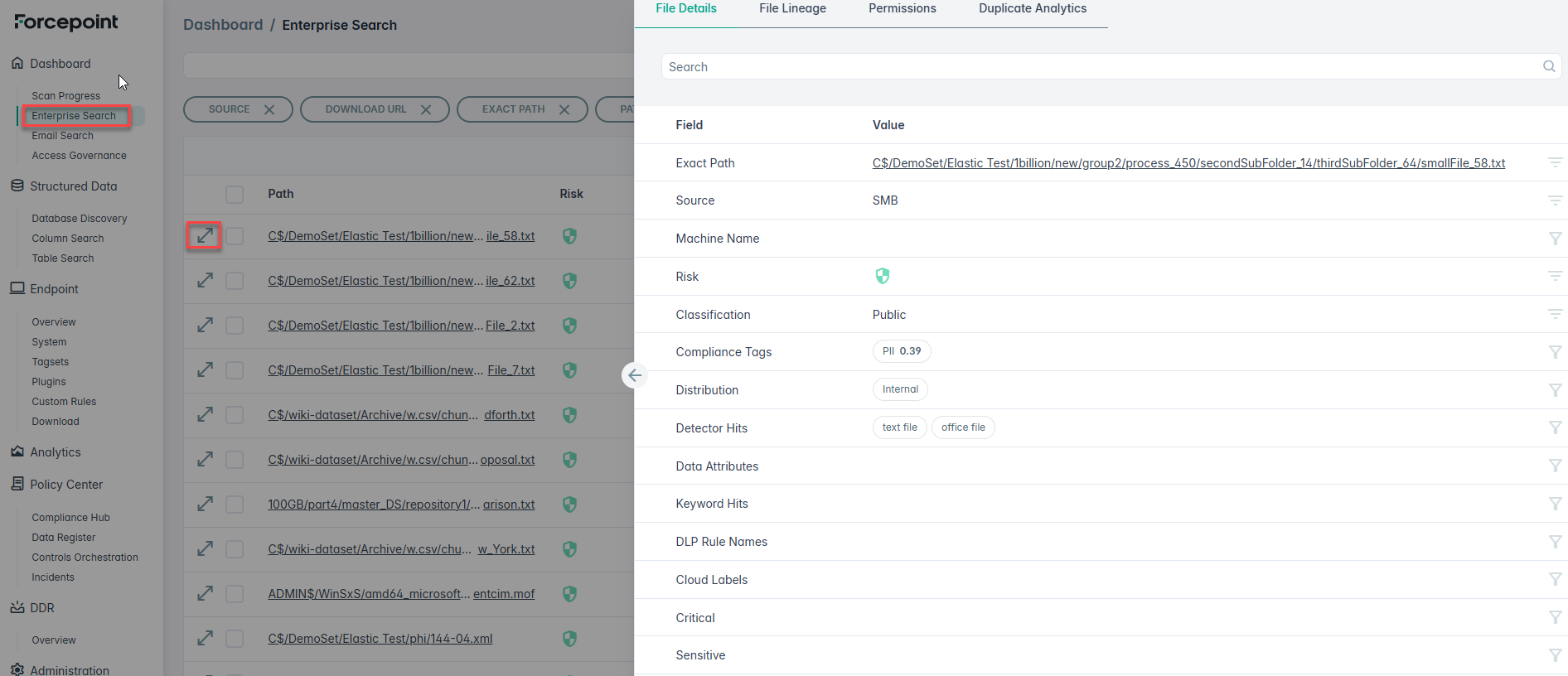
- Source / File ID / Configuration ID
- Ingested at timestamp
- Data Asset / Data Owners / Department
- Sharing flags (Anyone with link / External shared) - derived from permissions
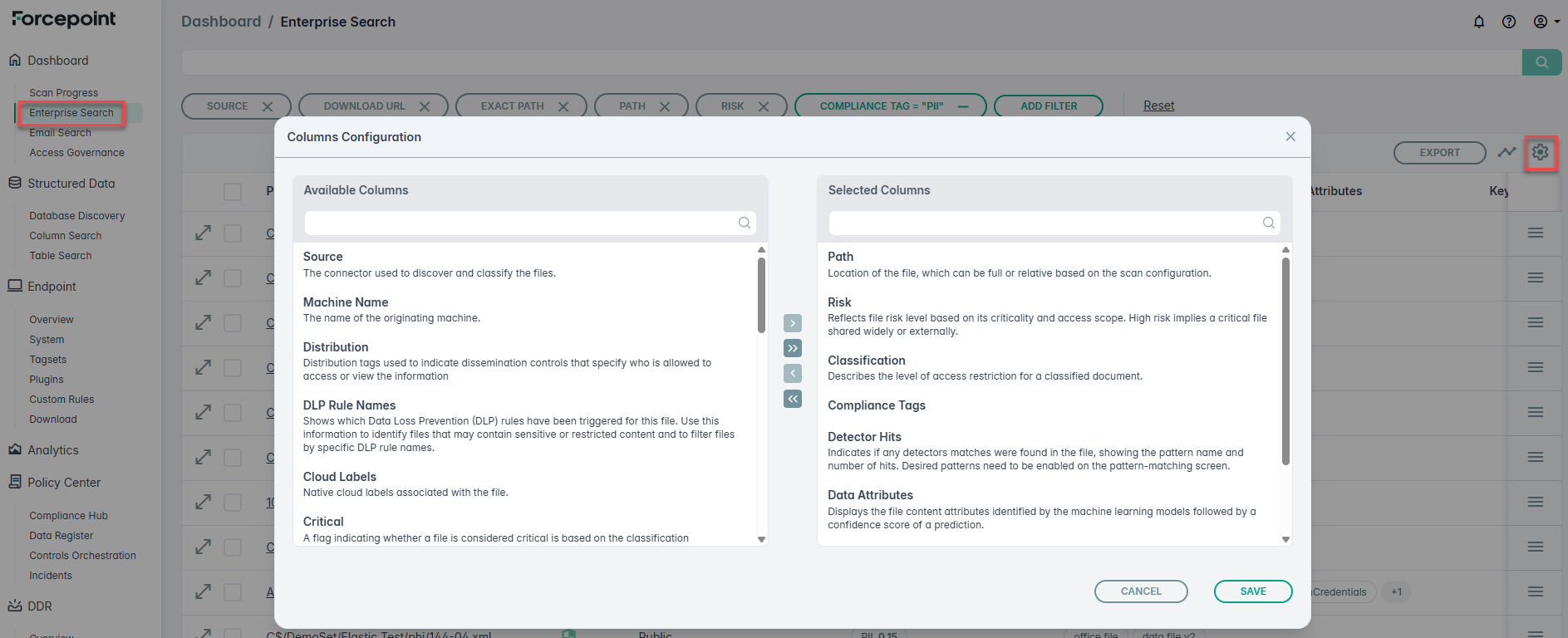
To view the metadata extracted during the Discovery and cataloging stage, navigate to Enterprise Search and add optional columns to display metadata fields.
Content Classification
Permissions are analyzed and the shared level is identified. A detailed analysis of each file's content is performed. Content is extracted and the sensitivity level and risk of each file is determined for classification. This is determined by the Patterns/Detector setting and the AI Mesh. This ensures that sensitive information is properly identified and protected.
- File content (text extraction, OCR)
Supported types of files
Forcepoint DSPM can scan the following file types:
- DOC
- RTF
- ODT
- ODS
- DOCX
- DOCM
- XLS
- XLSX
- XLSM
- PPT
- PPTX
- PPTM
- VSD
- TXT
- C
- H
- DESC
- CSV
- TSV
- XML
- XHTML
- HTML
- HTM
- EML
- MSG
- PNG
- JPG
- JPEG
- TIFF
- TIF